Natural Language Processing
1. Text processing in Python
Python is an object-oriented programming language. Examples of objects are strings, integers, real numbers, dataframes, and arrays. Objects have data (e.g. letters, numbers), attributes (e.g. length, dimensions), and methods (i.e. associated code).
In this part of he workshop we will explore Python string objects. A string object is simply an ordered string of symbols (mostly letters), with properties or attributes (e.g. length), and methods (code).
- 1.1 Strings and their properties
- 1.2 Strings as iterables
- 1.3 Lists
- 1.4 Comparing and searching strings
- 1.5 Regular expressions
1.1 Strings and their properties
Here is an example of a string:
'Peter Piper picked a peck of pickled peppers.'
Strings are designated by bounding single or double quotes.
This is a different string:
' Peter Piper picked a peck of pickled peppers. '
The length property of a string is evaluated with the len() function:
len(' Peter Piper picked a peck of pickled peppers. ')
Note that the length includes the spaces. The len() function can be used to evaluate the length, or size, or
many different Python objects; not just text.
Exercise: Use the
len()function to measure the length of the two strings above.
A ‘function’ is code that is independent of a specific object. A ‘method’ is code that is associated with an object. Use a period and the method name to access it, like this:
'Peter Piper picked'.upper()
Exercise: Assign a string to a variable
s = 'Peter Piper picked a peck of pickled peppers.'
What does the
upper()method do?
s.upper()
Explore the following string methods:
s.lower()
s.title()
s.count('p')
How often does ‘p’ appear in s? Count the occurences of ‘pe’?
What does this do?
s.lower().count('pe')
1.2 Strings as Iterables
A string is an ordered set of symbols: letters, numbers, and other characters. The position of each symbol can be ascertained with with .index() method. The following will return the position of ‘t’ in the string. Note that the first position is ‘0’, not ‘1’. This is known as ‘zero-based’ indexing.
opening = 'Once upon a time...'
print(opening.index('t'))
An object that consist of an ordered set of other objects is ‘iterable’, because you can iterate, or loop over those objects. A string consists of an ordered set of single-characters strings, so it is iterable. That is, ‘Once upon a time…’ consists of ‘O’, ‘n’, ‘c’, ‘e’, etc. The indexes of the characters are 0, 1, 2, 3, 4, etc.
Iterable objects can be looped over like this:
for character in opening:
print(character)
Note that the variable ‘character’ is totally arbitrary. It is good to use a variable name that aids understanding, but it can actually be anything at all. Change ‘character’ to ‘banana’ and the code will work just as well.
Exercise: Explain the output for the following:
for character in opening:
print(opening.index(character))
Python index notation can be used to identify the position of a character in a string. The general form is:
string[start:end:skip]
Negative numbers refer to distance from the end of the string.
Can you explain the following:
text = 'I like to eat a banana for breakfast.'
print(text[0])
print(text[25])
print(text[-1])
print(text[3:20:2])
print(text[-1::-1])
print(text.split()[-1::-1])
1.3 Lists
A Python list is another iterable object. Like a string it is an ordered set of objects:
a_list = [1, 2, 3, 1024]
another_list = ['Once', 'upon', 'a', 'time', '...']
Lists do not have to be homogeneous:
list3 = [1, 'Jack', 2, 'and the Beanstalk']
list4 = [list3, another_list, a_list]
The output from print(list4) should look like this:
[[1, 'Jack', 2, 'and the Beanstalk'], ['Once', 'upon', 'a', 'time', '...'], [1, 2, 3, 1024]]
Note that strings are enclosed in quotation marks, whereas variables (e.g. list3, list4) are not.
Exercise: What output would you expect from this?
for obj in list4:
print(obj)
Exercise: What output would you expect from this?
for obj in list4:
for subobj in obj:
print(subobj)
Try it out.
In NLP it is often useful to be able to change strings into lists and vice versa. The string methods .split()
and .join() make this easy.
string1.split(string2) splits string1 at all incidents of string2 and puts the result into a list. If string2
is omitted that split will be on spaces.
For example:
'Once upon a time ...'.split()
will return:
['Once', 'upon', 'a' 'time', '...']
But
'Once upon a time ...'.split('e')
will return:
['Onc', ' upon a tim', ' ...']
The .join() method does the opposite. string2.join(list) takes the elements in list and concatenates them
into a string with string 2 as a separator.
For instance:
another_list = ['Once', 'upon', 'a', 'time', '...']
' '.join(another_list)
will return:
'Once upon a time ...'
Exercise: What does the following return:
syllables = ['an', 'ti', 'di', 'ses', 'ta', 'blish', 'men', 'ta', 'ri', 'an', 'ism']
''.join(syllables)
1.4 Comparing and Searching Strings
The .find() method is used to find a string of characters in a string. It has the following syntax:
'a string'.find(value, begin, end)
where ‘value’ is the string to find, and begin and end are the beginning and ending positions of the search. For example:
'the quick brown fox jumped over the lazy dog'.find('the', 10)
will return 32
If the string is not found, -1 is returned.
Exercise: Here is code to count the number of words that contain the letter
o. Why does it give an incorrect answer? Can you correct the code?
text = 'The quick brown fox jumped over the lazy dog'
text_list = text.split()
numb = 0
for word in text_list:
if word.find('o') > 0:
numb += 1
print('number of words:', numb)
Strings can be compared using these operators
== |
is equal to |
!= |
is NOT equal to |
> |
is greater than, in unicode order |
>= |
is greater than or equal to, in unicode order |
< |
is less than, in unicode order |
<= |
is less than or equal to, in unicode order |
Exercise: Study this code to sort the words in ‘The quick brown fox jumped over the lazy dog.’ It is an example of the bubble sort algorithm, demonstrated here:
| Wikipedia CC BY-SA 3.0 |
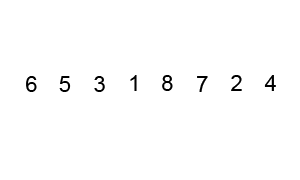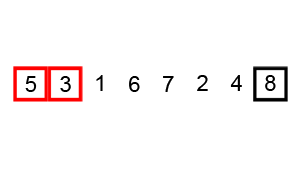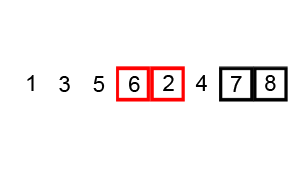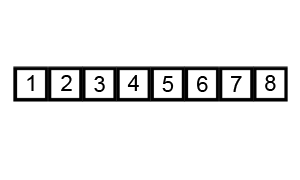 |
{kind=link}
Correct the code to make it work as you would expect.
text = 'The quick brown Fox jumped over the lazy Dog'.split()
len1 = len2 = len(text)-1
for looper in range(len1):
for pos in range(len2):
if text[pos] > text[pos+1]:
text[pos], text[pos+1] = text[pos+1], text[pos]
len2 -= 1
print(text)
1.5 Regular Expressions in Python
For a good introduction to regular expressions in Python see https://docs.python.org/3/howto/regex.html
Regular expressions (‘regex’) are templates for complex pattern matching of text that
provide more sophisticated matching than comparison operators and the .find() method.
Regular expressions are implemented in Python with the re module:
import re
Let’s use the following text for our examples. Note the use of triple quotes to delimit multi-line texts, and the presence of opening and closing quotes, apostrophe, and accented characters. These are all legitimate unicode characters, distinct from the straight quotes we use in our code.
footnote = '''I have taken the date of the first publication of Lamarck from
Isidore Geoffroy Saint-Hilaire’s (“Hist. Nat. Générale”, tom. ii. page
405, 1859) excellent history of opinion on this subject. In this work
a full account is given of Buffon’s conclusions on the same subject.
It is curious how largely my grandfather, Dr. Erasmus Darwin,
anticipated the views and erroneous grounds of opinion of Lamarck in
his “Zoonomia” (vol. i. pages 500-510), published in 1794. According
to Isid. Geoffroy there is no doubt that Goethe was an extreme
partisan of similar views, as shown in the introduction to a work
written in 1794 and 1795, but not published till long afterward; he
has pointedly remarked (“Goethe als Naturforscher”, von Dr. Karl
Meding, s. 34) that the future question for naturalists will be how,
for instance, cattle got their horns and not for what they are used.
It is rather a singular instance of the manner in which similar views
arise at about the same time, that Goethe in Germany, Dr. Darwin in
England, and Geoffroy Saint-Hilaire (as we shall immediately see) in
France, came to the same conclusion on the origin of species, in the
years 1794-5.'''
Let’s find ‘Darwin’ in our text using re
import re
result = re.search('Darwin', footnote)
print(result)
The following ‘match’ object is returned:
<re.Match object; span=(331, 337), match='Darwin'>
This tells you that the search was successful, and where the text was found:
footnote[331:337]
Using ‘metacharacters’ we are find a title that is bounded by opening/closing quotes:
searchterm = '“.+”'
result = re.search(searchterm, footnote)
print(result)
In the searchterm there are two metacharacters:
| . | matches any single character, except newline |
| + | matches one of more repetitions |
So, the search is for opening and closing quotes surrounding at least one character. This returns:
<re.Match object; span=(98, 119), match='“Hist. Nat. Générale”'>
The match object, result in this case, has the following methods and attribute:
| name | attribute or method | returns |
|---|---|---|
string |
attribute | the string passed into the function; footnote in this case |
span() |
method | a tuple containing the start and end of the text slice |
group() |
method | the matched part of the string |
start() |
method | the start index of the searchterm |
end() |
method | the end index of the searchterm |
Here is a complete code example of how these might be used:
import re
searchterm = '“.+”'
result = re.search(searchterm, footnote)
print('Title found:', result.group())
print('Start index:', result.start())
print('Ending index:', result.end())
We can alter this code to find all the matches using finditer() rather than search().
finditer() return an iterator that yields ALL the matches:
import re
searchterm = '“.+”'
results = re.finditer(searchterm, footnote)
for result in results:
print('Title found:', result.group())
print('Start index:', result.start())
print('Ending index:', result.end())
print()
Let’s make this code a function:
from re import finditer
def reprint(restring, texttosearch):
results = finditer(restring, texttosearch)
for result in results:
print('Title found:', result.group())
print('Start index:', result.start())
print('Ending index:', result.end())
print()
Exercise: What does this example do?
searchterm = '(p\.|page[s\s]|s\.)(\s+|\d+)+'
reprint(searchterm, footnote)