Chapter 6 Data Sharing
Sharing data that underlies research has become a common expectation within scholarly research. However, the landscape of data repositories is still uneven and many researchers are still learning best practices for data sharing. To help in this area, this chapter offers five exercises: a decision tree-inspired worksheet for picking the best data repository for your data; checklist for working through the process of sharing data in a data repository; a worksheet for writing a README file for shared data; and a checklist for making spreadsheets more accessible and reusable; and a formula for writing alt text for a data visualization.
6.1 Pick a Data Repository
Description: It can be difficult to know where to share research data as so many sharing platforms are available. Current guidance is to deposit data in data repository that will give you a DOI or similar permanent identifier. This exercise guides you through the process of picking a data repository, starting with repositories for very specific types of data and defaulting to generalist data repositories. Note that some repositories charge fees for deposit, most often for large data (500 GB or larger).
Instructions: Identify the data that needs to be shared and work through repository selection from discipline-specific data repositories to more general data repositories. Once you have identified a repository for all of your data, deposit the data and record the corresponding permanent identifiers. Note that, depending on data types, you may need to deposit your data into multiple repositories (for example, a discipline-specific repository for one type of data and an institutional data repository for the rest of the data).
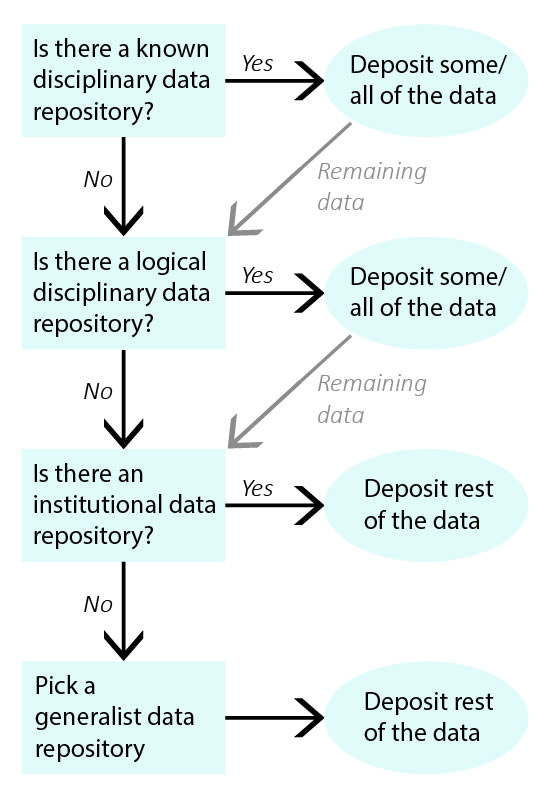
Workflow diagram upon which the exercise is based. Starting at the top, decide is there is a known disciplinary data repository (if so, deposit data), a logical disciplinary data repository (if so, deposit data), an institutional data repository (if so, deposit data), and if none of those work pick a generalist data repository.
1. Identify all of the data that needs to be shared.
Example: My data to be shared includes: 1) genetic data for Drosophila; and 2) microscope images of flies.
2. Is there a known disciplinary data repository for some or all of the data? For example, is there a data repository used by everyone in your research area or required for your data type by your funding agency?
If so, deposit some or all of your data there. Go to step 7 if the repository will accept all of your data or go to the next question if there is still some data left to deposit.
Example: The database FlyBase is used for Drosophila genes and genomes. My genetic data will be shared there.
3. Review the list of recommended data repositories from PLOS (PLOS ONE, 2023). Is there a logical disciplinary data repository for some or all of your data?
If so, deposit some or all of your data there. Go to step 7 if you have shared all of your data or go to the next question if there is still some data left to deposit.
Example: There isn’t a logical disciplinary data repository for microscope images of flies.
4. Does your institution have a data repository?
If so, deposit the remainder of your data there and go to step 7.
Example: The California Institute of Technology hosts the data repository CaltechDATA. I will deposit my microscope images in CaltechDATA.
5. Do you have a preferred generalist data repository (NIH, 2023)?
If so, deposit the remainder of your data there and go to step 7.
Example: [All data has been shared already.]
6. Pick a generalist data repository (NIH, 2023) and deposit the remainder of your data.
Deposit your data and go to step 7.
Example: [All data has been shared already.]
7. Record the permanent identifier, ideally a DOI, from each data deposit.
DOIs make data FAIR (Wilkinson et al., 2016) and aid with data sharing compliance. If you did not receive a permanent identifier (such as a DOI, permanent URL, etc.) during deposit, return to step 2 and pick a different data repository for your data.
Example: CaltechDATA provides DOIs for all deposits; my permanent identifier is doi.org/10.22002/XXXXXXXXXXX. FlyBase provides stable links to data reports using FlyBase ID numbers; my permanent identifier is flybase.org/reports/FBXXXXXXXXX.
6.3 Write a README File for Shared Data
Description: A README file can make the difference between not understanding a shared dataset and actually being able to reuse the data. A README file for shared data goes beyond basic information listed in a data repository by explaining what is in each file, how files relate to each other, and anything else someone needs to know to use a dataset. While you may not be required to include a README file when depositing data into a data repository, including a README file is almost always recommended.
Instructions: Fill out the worksheet for the collection data being shared. Each group of files being deposited into a repository should have an accompanying README file. Note that repositories for very specific types of data sometimes do not accept README files and instead ask for detailed information about the data during the deposit process.
Record the title of the dataset:
Example: Data from “Measuring data rot: an analysis of the continued availability of shared data from a single university”
List the dataset authors, identifying the corresponding author(s) and providing their contact information:
Example: Kristin Briney (briney@caltech.edu; ORCID: 0000-0003-1802-0184)
Briefly summarize the project these data files are from:
Example: This data is from a study of 2,000+ links to shared data from Caltech-authored publications. The links were web-scraped to test for the continued availability of the data.
If applicable, list any publications supported by this data:
Example: One article was published from this data: Briney, K. A. (2024). Measuring data rot: An analysis of the continued availability of shared data from a Single University. PLOS ONE, 19(6), e0304781. https://doi.org/10.1371/journal.pone.0304781
If applicable, record the funding source for this data:
Example: The author received no funding for this work.
Identify the license this data is being made available under:
Example: The data is available under a Creative Commons Zero v1.0 Universal license.
Write a list of all data files being shared and a short description of what each of these files contains:
Example:
- DataRot.csv: This data contains all of the links tested, listing results of the web-scraping but not results of the hand testing.
- DataRot_dataDictionary.txt: Data dictionary defining variable names and values for DataRot.csv.
- DataRot_handTested.csv: Subset of supplemental data links from DataRot.csv that were hand-tested and the results of the hand testing.
Describe any relationships between files:
Example: DataRot_handTested.csv is a subset of DataRot.csv that only includes the links that were tested by hand.
Is there any related data not shared here? If so, list that data, describe it briefly, and document how it can be accessed:
Example: The code used for web-scraping and analysis of this data is available at https://doi.org/10.22002/d2h9g-5q152 under a GNU General Public License v3.0.
For any spreadsheet files, create a data dictionary (see Exercise 2.3: Create a Data Dictionary).
Either copy the data dictionary contents here or share the data dictionary as a separate file (making sure to add the data dictionary to the above list of files and their descriptions).
Example: The data dictionary is available in the DataRot_dataDictionary.txt file.
What else should someone know about this dataset:
Example: The data is UTF-8 encoded. R version 4.1.1 was used for web-scraping and data analysis.
Save all of this information as a README.txt file (you can also use README.md when sharing software) and share with your data.
6.4 Make Spreadsheets More Accessible and Reusable
Description: Making your data both accessible and reusable makes it easier for someone (including your future self) to use and understand your data. Slight tweaks to formatting can make a significant difference to a spreadsheet’s reusability. This checklist provides guidance on making a spreadsheet reusable as well as more accessible to those with disabilities. Note that sometimes guidance for reusability and accessibility conflict, and this checklist is a best effort to balance the two considerations.
Instructions: For a given spreadsheet, work through the actions on this checklist to make that data more accessible and reusable. This is best done when the data is finalized and/or prior to sharing the data either publicly or with colleagues. It is recommended to also share data in its original form, but your data will be more FAIR (Wilkinson et al., 2016) when an accessible version is made available alongside the original.
Further Resources:
Organize the Data
__ Break data into several smaller rectangular tables instead of one large complex table, as necessary. Each sheet should contain only one table.
__ Arrange data so that the top row contains variable names, with data in all following rows. See Wickham’s guidelines on tidy data for more information (Wickham, 2014).
Make the Data Readable
__ Clean up the variable names in the first row of the spreadsheet to be both human and machine readable:
- Use short but meaningful names;
- Use full words or readable abbreviations (e.g. “number” or “num” instead of “n”) in variable names;
- Use only alphanumeric characters in variable names;
- Remove spaces from variable names;
- Capitalize the first letter of each word in the variable name, though the first word can be lower case depending on preference (e.g. myVariableName or MyVariableName).
__ Place the key, or most identifying, variable in the first column on the left, column A. (Spreadsheets should be readable from left to right then top to bottom, and placement of the key variable in the first column will help with readability.)
Clean the Data
__ Convert any dates to YYYY-MM-DD format. (To work around Excel’s weird date formatting you can separate year, month, and day into three separate variables.)
__ Ensure that spreadsheet cells contain only one data point. If there is more than one data point per cell, divide columns into multiple variables as appropriate.
__ Remove formatting such as font, text alignment, highlighting, and merged cells. Any information represented by such formatting should be recorded as data under new variable.
__ Fill in empty cells:
- Input any missing data values;
- Use “NA” (or the preferred null value for your analysis software) for any cells that do not have recorded values.
__ Perform quality control on the data, removing:
- Errors,
- Inconsistencies,
- Accidental spaces.
Format the Data
__ If using a spreadsheet editor other than Excel, enclose any cells containing commas inside of double quotes (e.g. “text, example”).
__ Remove charts. Charts may be shared separately with corresponding alt text.
__ Remove underlying calculations so that the file only includes raw data. (You can do this in Excel by copying a column, using the special paste option to “paste as values,” then deleting the original column.)
__ Use any built-in validation or accessibility checkers provided by your software.
Save and Share the Data
__ Save data as a CSV file type (TSV is also an acceptable file format). Save individual spreadsheet tabs as separate CSV files.
__ Create an accompanying data dictionary (see Exercise 2.3: Create a Data Dictionary).
__ Share the accessible CSV file(s), the original dataset, and the data dictionary.
6.5 Write Alt Text for a Scientific Data Visualization
Description: Writing alt text (short for “alternative text”) is one of the most basic ways to make a scientific figure accessible to a broader audience by providing a textual description of an image. Alt text is useful when sharing figures on your lab website, on social media, and even when publishing journal articles. Alt text is a basic requirement when sharing digital images.
Instructions: Answer questions 1-3 for each panel of a figure then assemble the answers using the formula in step 4. This formula for creating alt text comes from Amy Cesal at Nightingale (Cesal, 2021). It’s less accessible than a more complete description of a visualization or sharing the data underlying a visualization, but it’s a quick way to write usable alt text for a chart.
Further Resources:
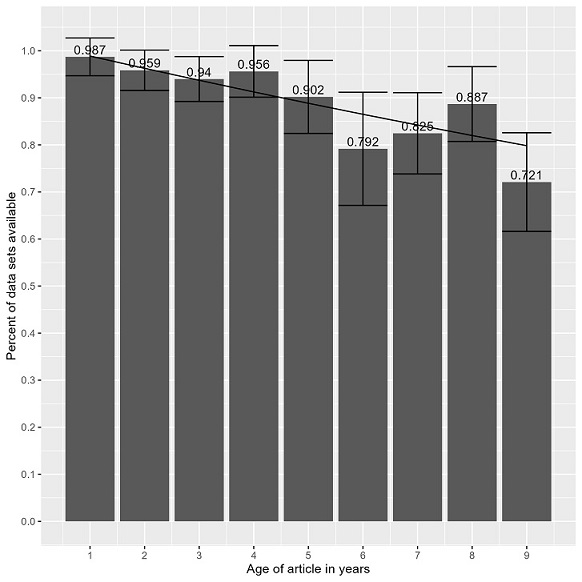
Figure used as the example for this exercise. Figure is from (K. A. Briney, 2024)
1. In 2-3 words, list the chart type:
Example: Column chart
2. Briefly summarize the primary data (e.g. y-axis data) that makes up this chart:
Example: Research data availability
3. In one sentence, write the main takeaway of the visualization:
Example: Research data on the internet disappears at a rate of 2.6% per year.
4. Write out the full alt text as: [Answer 1] of [answer 2] where [answer 3].
Example: Column chart of research data availability where research data on the internet disappears at a rate of 2.6% per year.
5. Where applicable, repeat steps 1-4 for each panel of a multi-panel figure. Note which part of the figure goes with each sentence.
Example: Not applicable
6. Where possible, include a link to the data underlying the figure.
Example: For underlying data, see “Figure2_UnavailableByYear.csv” file at https://doi.org/10.22002/h5e81-spf62
7. Share the alt text anytime you share the figure.